CS231n assignment1 : KNN
방학 동안 cs231n을 독학하는 것을 목표로 삼고 assignment를 colab을 이용해 차근차근 풀어보고 있다.
2017년 강의가 유튜브에 모두 업로드 되어 있는데, 강의 내용이 내가 지난 학기에 들었던 cs376(기계학습)과 상당히 유사해 강의 요약은 생략하고, assignment만 정리하기로 했다.
첫번째 assignment는 아래와 같이 세부적인 5가지 과제들로 구성되어 있고, 오늘은 이중에서 첫번째 과제인 knn에 대해 다루고자 한다.

과제를 수행하기 전, 아래 링크에 있는 assignment 1 튜토리얼 영상을 참고하면 이해하기 쉽다.
https://cs231n.github.io/assignments2023/assignment1/
Assignment 1
This assignment is due on Friday, April 21 2023 at 11:59pm PST. Starter code containing Colab notebooks can be downloaded here. Setup Please familiarize yourself with the recommended workflow before starting the assignment. You should also watch the Colab
cs231n.github.io
아래 보이는 화면처럼 왼쪽에 knn.ipynb 코드와 오른쪽에 k_nearest_neighbor.py 코드를 띄워놓은 뒤 작업하면 코드를 작성하고 실행하는 것이 한결 수월하다.

우리가 학습에 사용할 data는 아래와 같다. (X_train, X_test)
이때 classifier을 이용해 KNearestNeighbor 내의 여러 함수들을 사용하는데, 위에 첨부한 사진에서 오른쪽에 있는 코드(k_nearest_neighbor.py)를 불러온다고 이해하면 쉽다.

본격적인 코드 작성은 아래부터 시작된다.
아래 코드의 출력이 아래 사진처럼 제대로 나온다면, 코드 작성을 시작하기 전 기본 세팅은 제대로 된 상태라고 볼 수 있다. 제대로 나오지 않는다면, function compute_distances_two_loops를 잘 썼는지 확인해보자. two_loop이므로 이중 for문을 사용해도 됨에 유의하자.


첫번째 퀴즈의 답안은 아래와 같이 작성했다. 잘못된 내용이 있다면 댓글로 알려주길 바란다.

아래 코드를 돌리기 위해 fuction predict_labels을 작성하였다.
accurancy가 약 27% 정도 나오면 성공이다.

작성한 함수 predict_labels는 아래와 같다.

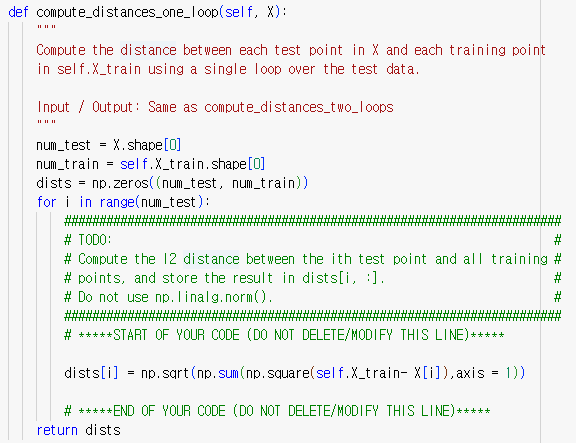
다음 코드를 실행하기 위해서는 k_nearest_neighbor.py의 function compute_distances_one_loop 코드를 작성해야한다. for loop을 하나만 사용하여 아래와 같이 코드를 작성하였다.
만약 코드 이해가 잘 되지 않는다면, numpy에서 사용되는 broadcasting 관련 개념을 더 공부하고 오길 바란다.

마지막은 반복문을 아예 사용하지 않고 코드를 작성하는 경우이다. 이 경우는 아이디어를 내는게 너무너무 힘들었다... 오랜 시간이 걸려도 이상하지 않으니... 깊게 생각해보길 바란다.


다음으로 각각의 코드별로 시간을 비교하는 코드가 나온다. 주석을 읽어보면 알겠지만, one loop version이 더 오랜 시간이 걸리는 것이 맞으니 이상하게 생각하지 말자..! 반면 no loop 코드는 압도적으로 빠르다는 것을 확인할 수 있다!

이후 cross validation을 실행하는 코드가 나오고
마지막엔 k 값에 따라 cross validation accurancy가 어떻게 나오는지 비교하는 graph를 그린다.
마지막 graph를 보고 어떤 k값을 선택해야할지를 고민해볼 수 있다.


graph를 보면 대략 k값이 10일 때 accurancy가 높게 나타남을 확인할 수 있다. 이에 따라 마지막 코드에 k= 10의 값을 넣어주면, 0.282의 accurancy 값을 가짐을 확인할 수 있다. 다른 k값을 넣으면서 언제 accurancy가 가장 큰 값을 갖는지 비교해보자. (다 넣어보면 알겠지만 k= 10일 때가 가장 크게 나타난다.)

마지막 질문의 답은 아래와 같이 작성하였다.

참고로 과제를 해결한지 3주가 지난 시점에서 블로그를 작성하다보니 상당 부분이 잘 기억나지 않아 설명이 생략되었다. 잘못된 설명이 있다면 댓글에 적어주길 바란다.